Type this command in linux shell for converting OGV video files to AVI:
mencoder foo.ogv -o foo.avi -oac mp3lame -lameopts fast:preset=standard -ovc lavc -lavcopts vcodec=mpeg4:vbitrate=4000
Converted video is directly uploadable for youtube.
Friday, December 3, 2010
Monday, November 29, 2010
Thursday, November 25, 2010
Simple Matrix Operations for the C Language
- Creating matrices
- Summation
- Subtraction
- Multiplication
- Multiplication with a scaler
- Inverse
- Determinant
- Echelon Form
- Submatrix extraction
- Saving and loading matrices
This is an open source project under the GPL. That means you can use and change it for any purpose but you have to make the source codes public.
The header file and an example are given below. Also you can download the source code by clicking here.
An example is given below:
/*================================================================ matrix, a simple library for matrix operations. Copyright (C) 2010-2011 by Mehmet Hakan Satman. This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License version 2 as published by the Free Software Foundation. This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details. You should have received a copy of the GNU General Public License along with this program; if not, write to the Free Software Foundation, Inc., 51 Franklin St, Fifth Floor, Boston, MA 02110-1301
USA The author may be reached at mhsatman@yahoo.com. *============================================================*/ #include <stdio.h> #include <stdlib.h> #include "matrix.h" int main() { int n=10; int m=10; /* Creating a matrix with rows n, columns m */ Matrix *m1=Matrix_create(n,m); Matrix *m2; /* Randomizing the matrix. */ int i,j; double val=1; for (i=0;i<n;i++){ for(j=0;j<m;j++){ val=((double)random()/RAND_MAX)*1; if(((double)random()/RAND_MAX)<0.5) val*=-1; Matrix_set(m1,i,j,val); } } /* Dumping the content of the matrix */ Matrix_dump(m1); /* Getting inverse of the matrix. */ m1=Matrix_inverse(m1); /* Getting the second column of the matrix */ m2=Matrix_getcol(m1,1); /* Saving matrices */ Matrix_save(m1,"matrix1.dat"); Matrix_save(m2,"matrix2.dat"); /* Reloading matrices */ m1=Matrix_load("matrix1.dat"); m2=Matrix_load("matrix2.dat"); /* Calculating determinant */ printf("Determinant of m1 is %f\n", Matrix_determinant(m1)); //this will return nan, becase m2 is not a square matrix printf("Determinant of m2 is %f\n", Matrix_determinant(m2)); /* Free the memory */ Matrix_delete(m1); Matrix_delete(m2); printf("OK\n"); return(0); }The main page of this library is http://www.mhsatman.com/
Monday, November 22, 2010
Download Dos 6.22
Yes! Microsoft must pay us for using this :)
Download Dos 6.22 For Free
Thursday, November 11, 2010
Calling R from Java - RCaller
Edit: This version of RCaller is deprecated, please check the new version of 2.0. This entry is about older versions of RCaller and may be outdated. A blog entry for version 2.0 is in http://stdioe.blogspot.com/2011/07/rcaller-20-calling-r-from-java.html and http://stdioe.blogspot.com.tr/2014/04/rcaller-220-is-released.html for RCaller version 2.2New version : Rcaller 0.5.2Note: The source page of this article is http://www.mhsatman.com/rcaller.php | ||||||||||||||
| [2010/08/07] Now, Rcaller has a new version, 0.5.2, with some bug fixes and additional functionality. Some changes are done and some bugs are fixed by John Oliver. John is now second developer of the Rcaller. | ||||||||||||||
Change Log for version 0.5.2: | ||||||||||||||
| ||||||||||||||
RCaller | ||||||||||||||
| RCaller is an other simple way to call R from Java without JNI. There are lots of queries in the internet about "how to call r from java" or "call r function from java with / without JNI". There are some solutions about these works, for example, RServe is a server application written in C and it waits for socket connections, then accepts clients and runs the R code that sent from socket streams and returns SEXP 's (S / R Expressions). Also, rJava is a JNI solution for calling R from Java. But as i see, users don't want to struggle this things and they seeks more practical solutions. RCaller uses neither sockets nor JNI interface for calling R functions from Java. RCaller simply runs RScript executable file using java's Runtime and Process classes. Then runs R commands using arguments and handles results using streams. RCaller converts R objects to Java's double or String arrays using a R script and BeanShell interpreter. After these operations R results can be handled by user using getter methods. You can use it in your Java applications that needs some statistical calculations. Implementation and setting-up processes are easy. You can download source codes as Netbeans project and jars. Simply add two jars to your classpath and start calling R! | ||||||||||||||
Examples | ||||||||||||||
1)Getting Pi from R!In this example, we are calling R code "a<-pi;" that sets the value of pi to variable a. Then, we handle this result from Java.
The result is 3.14159. RCaller always handles results as arrays, so a is not variable but double array. Array has only one element, so a[0] is the value that sent from R. We have to use cat(makejava(a)) to make R object 'a' usable in Java. We call RunRCode() function with 3 parameters. Last 2 parameters are boolean. If first one is true, then content of stderr will be written on console. If the second one is true, then content of stdout will be written. We set them false not to write both outputs on the screen. | ||||||||||||||
2)Calculate Linear Regression from Java using RIn this example, we set x and y with random variables that come from standard normal distributions and estimate linear regression using R and Java.
The result is -0.815634476060036
0.637334790434423
so, these are the estimated coefficients of the ordinary least squres regression. | ||||||||||||||
3)Running RCaller in different platforms (Linux, Windows, Mac, etc)RCaller is pure Java and can be run any platform that Java virtual machine runs. Also, you need to be have R as well. Default R engine is Rscript executable file that distrubited in R. Default value of engine is /usr/bin/Rscript but user can change location using setRScriptExecutableFile(String location) method.
| ||||||||||||||
4)What objects returned after running my R command?RCaller converts R objects to Java objects. You can handle returned values' names like this:
The result is: double[] residuals
double[] coefficients
double[] sigma
double[] df
double[] rsquared
double[] adjrsquared
double[] fstatistic
double[] covunscaled
double[] residuals
double[] coefficients
double[] sigma
double[] df
double[] rsquared
double[] adjrsquared
double[] fstatistic
double[] covunscaled
and these are all returned fields from the summary() R command. | ||||||||||||||
Download source code and jars
| ||||||||||||||
| If you like this solution or you have got any questions, you can send e-mail using mhsatman [at] yahoo.com. Mehmet Hakan Satman, Istanbul University, Faculty of Economics, Department of Econometrics | ||||||||||||||
Tuesday, September 7, 2010
Top 20+ MySQL Best Practices
Note: This article was taken from http://net.tutsplus.com/tutorials/other/top-20-mysql-best-practices/comment-page-3/
 Database operations often tend to be the main bottleneck for most web applications today. It’s not only the DBA’s (database administrators) that have to worry about these performance issues. We as programmers need to do our part by structuring tables properly, writing optimized queries and better code. Here are some MySQL optimization techniques for programmers.
Database operations often tend to be the main bottleneck for most web applications today. It’s not only the DBA’s (database administrators) that have to worry about these performance issues. We as programmers need to do our part by structuring tables properly, writing optimized queries and better code. Here are some MySQL optimization techniques for programmers.
The main problem is, it is so easy and hidden from the programmer, most of us tend to ignore it. Some things we do can actually prevent the query cache from performing its task.
The reason query cache does not work in the first line is the usage of the CURDATE() function. This applies to all non-deterministic functions like NOW() and RAND() etc… Since the return result of the function can change, MySQL decides to disable query caching for that query. All we needed to do is to add an extra line of PHP before the query to prevent this from happening.
The results of an EXPLAIN query will show you which indexes are being utilized, how the table is being scanned and sorted etc…
Take a SELECT query (preferably a complex one, with joins), and add the keyword EXPLAIN in front of it. You can just use phpmyadmin for this. It will show you the results in a nice table. For example, let’s say I forgot to add an index to a column, which I perform joins on:
 After adding the index to the group_id field:
After adding the index to the group_id field:
 Now instead of scanning 7883 rows, it will only scan 9 and 16 rows from the 2 tables. A good rule of thumb is to multiply all numbers under the “rows” column, and your query performance will be somewhat proportional to the resulting number.
Now instead of scanning 7883 rows, it will only scan 9 and 16 rows from the 2 tables. A good rule of thumb is to multiply all numbers under the “rows” column, and your query performance will be somewhat proportional to the resulting number.
In such cases, adding LIMIT 1 to your query can increase performance. This way the database engine will stop scanning for records after it finds just 1, instead of going thru the whole table or index.
 As you can see, this rule also applies on a partial string search like “last_name LIKE ‘a%’”. When searching from the beginning of the string, MySQL is able to utilize the index on that column.
As you can see, this rule also applies on a partial string search like “last_name LIKE ‘a%’”. When searching from the beginning of the string, MySQL is able to utilize the index on that column.
You should also understand which kinds of searches can not use the regular indexes. For instance, when searching for a word (e.g. “WHERE post_content LIKE ‘%apple%’”), you will not see a benefit from a normal index. You will be better off using mysql fulltext search or building your own indexing solution.
Also, the columns that are joined, need to be the same type. For instance, if you join a DECIMAL column, to an INT column from another table, MySQL will be unable to use at least one of the indexes. Even the character encodings need to be the same type for string type columns.
If you really need random rows out of your results, there are much better ways of doing it. Granted it takes additional code, but you will prevent a bottleneck that gets exponentially worse as your data grows. The problem is, MySQL will have to perform RAND() operation (which takes processing power) for every single row in the table before sorting it and giving you just 1 row.
So you pick a random number less than the number of results and use that as the offset in your LIMIT clause.
It is a good habit to always specify which columns you need when you are doing your SELECT’s.
Even if you have a users table that has a unique username field, do not make that your primary key. VARCHAR fields as primary keys are slower. And you will have a better structure in your code by referring to all users with their id’s internally.
There are also behind the scenes operations done by the MySQL engine itself, that uses the primary key field internally. Which become even more important, the more complicated the database setup is. (clusters, partitioning etc…).
One possible exception to the rule are the “association tables”, used for the many-to-many type of associations between 2 tables. For example a “posts_tags” table that contains 2 columns: post_id, tag_id, that is used for the relations between two tables named “post” and “tags”. These tables can have a PRIMARY key that contains both id fields.
If you have a field, which will contain only a few different kinds of values, use ENUM instead of VARCHAR. For example, it could be a column named “status”, and only contain values such as “active”, “inactive”, “pending”, “expired” etc…
There is even a way to get a “suggestion” from MySQL itself on how to restructure your table. When you do have a VARCHAR field, it can actually suggest you to change that column type to ENUM instead. This done using the PROCEDURE ANALYSE() call. Which brings us to:
For example, if you created an INT field for your primary key, however do not have too many rows, it might suggest you to use a MEDIUMINT instead. Or if you are using a VARCHAR field, you might get a suggestion to convert it to ENUM, if there are only few unique values.
You can also run this by clicking the “Propose table structure” link in phpmyadmin, in one of your table views.
 Keep in mind these are only suggestions. And if your table is going to grow bigger, they may not even be the right suggestions to follow. The decision is ultimately yours.
Keep in mind these are only suggestions. And if your table is going to grow bigger, they may not even be the right suggestions to follow. The decision is ultimately yours.
First of all, ask yourself if there is any difference between having an empty string value vs. a NULL value (for INT fields: 0 vs. NULL). If there is no reason to have both, you do not need a NULL field. (Did you know that Oracle considers NULL and empty string as being the same?)
NULL columns require additional space and they can add complexity to your comparison statements. Just avoid them when you can. However, I understand some people might have very specific reasons to have NULL values, which is not always a bad thing.
From MySQL docs:
Prepared Statements will filter the variables you bind to them by default, which is great for protecting your application against SQL injection attacks. You can of course filter your variables manually too, but those methods are more prone to human error and forgetfulness by the programmer. This is less of an issue when using some kind of framework or ORM.
Since our focus is on performance, I should also mention the benefits in that area. These benefits are more significant when the same query is being used multiple times in your application. You can assign different values to the same prepared statement, yet MySQL will only have to parse it once.
Also latest versions of MySQL transmits prepared statements in a native binary form, which are more efficient and can also help reduce network delays.
There was a time when many programmers used to avoid prepared statements on purpose, for a single important reason. They were not being cached by the MySQL query cache. But since sometime around version 5.1, query caching is supported too.
To use prepared statements in PHP you check out the mysqli extension or use a database abstraction layer like PDO.
There is a great explanation in the PHP docs for the mysql_unbuffered_query() function:
You have to make sure your column is an UNSIGNED INT, because IP Addresses use the whole range of a 32 bit unsigned integer.
In your queries you can use the INET_ATON() to convert and IP to an integer, and INET_NTOA() for vice versa. There are also similar functions in PHP called ip2long() and long2ip().
Fixed-length tables can improve performance because it is faster for MySQL engine to seek through the records. When it wants to read a specific row in a table, it can quickly calculate the position of it. If the row size is not fixed, every time it needs to do a seek, it has to consult the primary key index.
They are also easier to cache and easier to reconstruct after a crash. But they also can take more space. For instance, if you convert a VARCHAR(20) field to a CHAR(20) field, it will always take 20 bytes of space regardless of what is it in.
By using “Vertical Partitioning” techniques, you can separate the variable-length columns to a separate table. Which brings us to:
Example 1: You might have a users table that contains home addresses, that do not get read often. You can choose to split your table and store the address info on a separate table. This way your main users table will shrink in size. As you know, smaller tables perform faster.
Example 2: You have a “last_login” field in your table. It updates every time a user logs in to the website. But every update on a table causes the query cache for that table to be flushed. You can put that field into another table to keep updates to your users table to a minimum.
But you also need to make sure you don’t constantly need to join these 2 tables after the partitioning or you might actually suffer performance decline.
Apache runs many parallel processes/threads. Therefore it works most efficiently when scripts finish executing as soon as possible, so the servers do not experience too many open connections and processes at once that consume resources, especially the memory.
If you end up locking your tables for any extended period of time (like 30 seconds or more), on a high traffic web site, you will cause a process and query pileup, which might take a long time to clear or even crash your web server.
If you have some kind of maintenance script that needs to delete large numbers of rows, just use the LIMIT clause to do it in smaller batches to avoid this congestion.
MySQL docs have a list of Storage Requirements for all data types.
If a table is expected to have very few rows, there is no reason to make the primary key an INT, instead of MEDIUMINT, SMALLINT or even in some cases TINYINT. If you do not need the time component, use DATE instead of DATETIME.
Just make sure you leave reasonable room to grow or you might end up like Slashdot.
MyISAM is good for read-heavy applications, but it doesn't scale very well when there are a lot of writes. Even if you are updating one field of one row, the whole table gets locked, and no other process can even read from it until that query is finished. MyISAM is very fast at calculating SELECT COUNT(*) types of queries.
InnoDB tends to be a more complicated storage engine and can be slower than MyISAM for most small applications. But it supports row-based locking, which scales better. It also supports some more advanced features such as transactions.
ORM's are great for "Lazy Loading". It means that they can fetch values only as they are needed. But you need to be careful with them or you can end up creating to many mini-queries that can reduce performance.
ORM's can also batch your queries into transactions, which operate much faster than sending individual queries to the database.
Currently my favorite ORM for PHP is Doctrine. I wrote an article on how to install Doctrine with CodeIgniter.
It sounds great in theory. But from my personal experience (and many others), this features turns out to be not worth the trouble. You can have serious problems with connection limits, memory issues and so on.
Apache runs extremely parallel, and creates many child processes. This is the main reason that persistent connections do not work very well in this environment. Before you consider using the mysql_pconnect() function, consult your system admin.
1. Optimize Your Queries For the Query Cache
Most MySQL servers have query caching enabled. It’s one of the most effective methods of improving performance, that is quietly handled by the database engine. When the same query is executed multiple times, the result is fetched from the cache, which is quite fast.The main problem is, it is so easy and hidden from the programmer, most of us tend to ignore it. Some things we do can actually prevent the query cache from performing its task.
- // query cache does NOT work
- $r = mysql_query("SELECT username FROM user WHERE signup_date >= CURDATE()");
- // query cache works!
- $today = date("Y-m-d");
- $r = mysql_query("SELECT username FROM user WHERE signup_date >= '$today'");
2. EXPLAIN Your SELECT Queries
Using the EXPLAIN keyword can give you insight on what MySQL is doing to execute your query. This can help you spot the bottlenecks and other problems with your query or table structures.The results of an EXPLAIN query will show you which indexes are being utilized, how the table is being scanned and sorted etc…
Take a SELECT query (preferably a complex one, with joins), and add the keyword EXPLAIN in front of it. You can just use phpmyadmin for this. It will show you the results in a nice table. For example, let’s say I forgot to add an index to a column, which I perform joins on:
3. LIMIT 1 When Getting a Unique Row
Sometimes when you are querying your tables, you already know you are looking for just one row. You might be fetching a unique record, or you might just be just checking the existence of any number of records that satisfy your WHERE clause.In such cases, adding LIMIT 1 to your query can increase performance. This way the database engine will stop scanning for records after it finds just 1, instead of going thru the whole table or index.
- // do I have any users from Alabama?
- // what NOT to do:
- $r = mysql_query("SELECT * FROM user WHERE state = 'Alabama'");
- if (mysql_num_rows($r) > 0) {
- // ...
- }
- // much better:
- $r = mysql_query("SELECT 1 FROM user WHERE state = 'Alabama' LIMIT 1");
- if (mysql_num_rows($r) > 0) {
- // ...
- }
4. Index the Search Fields
Indexes are not just for the primary keys or the unique keys. If there are any columns in your table that you will search by, you should almost always index them.You should also understand which kinds of searches can not use the regular indexes. For instance, when searching for a word (e.g. “WHERE post_content LIKE ‘%apple%’”), you will not see a benefit from a normal index. You will be better off using mysql fulltext search or building your own indexing solution.
5. Index and Use Same Column Types for Joins
If your application contains many JOIN queries, you need to make sure that the columns you join by are indexed on both tables. This affects how MySQL internally optimizes the join operation.Also, the columns that are joined, need to be the same type. For instance, if you join a DECIMAL column, to an INT column from another table, MySQL will be unable to use at least one of the indexes. Even the character encodings need to be the same type for string type columns.
- // looking for companies in my state
- $r = mysql_query("SELECT company_name FROM users
- LEFT JOIN companies ON (users.state = companies.state)
- WHERE users.id = $user_id");
- // both state columns should be indexed
- // and they both should be the same type and character encoding
- // or MySQL might do full table scans
6. Do Not ORDER BY RAND()
This is one of those tricks that sound cool at first, and many rookie programmers fall for this trap. You may not realize what kind of terrible bottleneck you can create once you start using this in your queries.If you really need random rows out of your results, there are much better ways of doing it. Granted it takes additional code, but you will prevent a bottleneck that gets exponentially worse as your data grows. The problem is, MySQL will have to perform RAND() operation (which takes processing power) for every single row in the table before sorting it and giving you just 1 row.
- // what NOT to do:
- $r = mysql_query("SELECT username FROM user ORDER BY RAND() LIMIT 1");
- // much better:
- $r = mysql_query("SELECT count(*) FROM user");
- $d = mysql_fetch_row($r);
- $rand = mt_rand(0,$d[0] - 1);
- $r = mysql_query("SELECT username FROM user LIMIT $rand, 1");
7. Avoid SELECT *
The more data is read from the tables, the slower the query will become. It increases the time it takes for the disk operations. Also when the database server is separate from the web server, you will have longer network delays due to the data having to be transferred between the servers.It is a good habit to always specify which columns you need when you are doing your SELECT’s.
- // not preferred
- $r = mysql_query("SELECT * FROM user WHERE user_id = 1");
- $d = mysql_fetch_assoc($r);
- echo "Welcome {$d['username']}";
- // better:
- $r = mysql_query("SELECT username FROM user WHERE user_id = 1");
- $d = mysql_fetch_assoc($r);
- echo "Welcome {$d['username']}";
- // the differences are more significant with bigger result sets
8. Almost Always Have an id Field
In every table have an id column that is the PRIMARY KEY, AUTO_INCREMENT and one of the flavors of INT. Also preferably UNSIGNED, since the value can not be negative.Even if you have a users table that has a unique username field, do not make that your primary key. VARCHAR fields as primary keys are slower. And you will have a better structure in your code by referring to all users with their id’s internally.
There are also behind the scenes operations done by the MySQL engine itself, that uses the primary key field internally. Which become even more important, the more complicated the database setup is. (clusters, partitioning etc…).
One possible exception to the rule are the “association tables”, used for the many-to-many type of associations between 2 tables. For example a “posts_tags” table that contains 2 columns: post_id, tag_id, that is used for the relations between two tables named “post” and “tags”. These tables can have a PRIMARY key that contains both id fields.
9. Use ENUM over VARCHAR
ENUM type columns are very fast and compact. Internally they are stored like TINYINT, yet they can contain and display string values. This makes them a perfect candidate for certain fields.If you have a field, which will contain only a few different kinds of values, use ENUM instead of VARCHAR. For example, it could be a column named “status”, and only contain values such as “active”, “inactive”, “pending”, “expired” etc…
There is even a way to get a “suggestion” from MySQL itself on how to restructure your table. When you do have a VARCHAR field, it can actually suggest you to change that column type to ENUM instead. This done using the PROCEDURE ANALYSE() call. Which brings us to:
10. Get Suggestions with PROCEDURE ANALYSE()
PROCEDURE ANALYSE() will let MySQL analyze the columns structures and the actual data in your table to come up with certain suggestions for you. It is only useful if there is actual data in your tables because that plays a big role in the decision making.For example, if you created an INT field for your primary key, however do not have too many rows, it might suggest you to use a MEDIUMINT instead. Or if you are using a VARCHAR field, you might get a suggestion to convert it to ENUM, if there are only few unique values.
You can also run this by clicking the “Propose table structure” link in phpmyadmin, in one of your table views.
11. Use NOT NULL If You Can
Unless you have a very specific reason to use a NULL value, you should always set your columns as NOT NULL.First of all, ask yourself if there is any difference between having an empty string value vs. a NULL value (for INT fields: 0 vs. NULL). If there is no reason to have both, you do not need a NULL field. (Did you know that Oracle considers NULL and empty string as being the same?)
NULL columns require additional space and they can add complexity to your comparison statements. Just avoid them when you can. However, I understand some people might have very specific reasons to have NULL values, which is not always a bad thing.
From MySQL docs:
“NULL columns require additional space in the row to record whether their values are NULL. For MyISAM tables, each NULL column takes one bit extra, rounded up to the nearest byte.”
12. Prepared Statements
There are multiple benefits to using prepared statements, both for performance and security reasons.Prepared Statements will filter the variables you bind to them by default, which is great for protecting your application against SQL injection attacks. You can of course filter your variables manually too, but those methods are more prone to human error and forgetfulness by the programmer. This is less of an issue when using some kind of framework or ORM.
Since our focus is on performance, I should also mention the benefits in that area. These benefits are more significant when the same query is being used multiple times in your application. You can assign different values to the same prepared statement, yet MySQL will only have to parse it once.
Also latest versions of MySQL transmits prepared statements in a native binary form, which are more efficient and can also help reduce network delays.
There was a time when many programmers used to avoid prepared statements on purpose, for a single important reason. They were not being cached by the MySQL query cache. But since sometime around version 5.1, query caching is supported too.
To use prepared statements in PHP you check out the mysqli extension or use a database abstraction layer like PDO.
- // create a prepared statement
- if ($stmt = $mysqli->prepare("SELECT username FROM user WHERE state=?")) {
- // bind parameters
- $stmt->bind_param("s", $state);
- // execute
- $stmt->execute();
- // bind result variables
- $stmt->bind_result($username);
- // fetch value
- $stmt->fetch();
- printf("%s is from %s\n", $username, $state);
- $stmt->close();
- }
13. Unbuffered Queries
Normally when you perform a query from a script, it will wait for the execution of that query to finish before it can continue. You can change that by using unbuffered queries.There is a great explanation in the PHP docs for the mysql_unbuffered_query() function:
“mysql_unbuffered_query() sends the SQL query query to MySQL without automatically fetching and buffering the result rows as mysql_query() does. This saves a considerable amount of memory with SQL queries that produce large result sets, and you can start working on the result set immediately after the first row has been retrieved as you don’t have to wait until the complete SQL query has been performed.”However, it comes with certain limitations. You have to either read all the rows or call mysql_free_result() before you can perform another query. Also you are not allowed to use mysql_num_rows() or mysql_data_seek() on the result set.
14. Store IP Addresses as UNSIGNED INT
Many programmers will create a VARCHAR(15) field without realizing they can actually store IP addresses as integer values. With an INT you go down to only 4 bytes of space, and have a fixed size field instead.You have to make sure your column is an UNSIGNED INT, because IP Addresses use the whole range of a 32 bit unsigned integer.
In your queries you can use the INET_ATON() to convert and IP to an integer, and INET_NTOA() for vice versa. There are also similar functions in PHP called ip2long() and long2ip().
- $r = "UPDATE users SET ip = INET_ATON('{$_SERVER['REMOTE_ADDR']}') WHERE user_id = $user_id";
15. Fixed-length (Static) Tables are Faster
When every single column in a table is “fixed-length”, the table is also considered “static” or “fixed-length”. Examples of column types that are NOT fixed-length are: VARCHAR, TEXT, BLOB. If you include even just 1 of these types of columns, the table ceases to be fixed-length and has to be handled differently by the MySQL engine.Fixed-length tables can improve performance because it is faster for MySQL engine to seek through the records. When it wants to read a specific row in a table, it can quickly calculate the position of it. If the row size is not fixed, every time it needs to do a seek, it has to consult the primary key index.
They are also easier to cache and easier to reconstruct after a crash. But they also can take more space. For instance, if you convert a VARCHAR(20) field to a CHAR(20) field, it will always take 20 bytes of space regardless of what is it in.
By using “Vertical Partitioning” techniques, you can separate the variable-length columns to a separate table. Which brings us to:
16. Vertical Partitioning
Vertical Partitioning is the act of splitting your table structure in a vertical manner for optimization reasons.Example 1: You might have a users table that contains home addresses, that do not get read often. You can choose to split your table and store the address info on a separate table. This way your main users table will shrink in size. As you know, smaller tables perform faster.
Example 2: You have a “last_login” field in your table. It updates every time a user logs in to the website. But every update on a table causes the query cache for that table to be flushed. You can put that field into another table to keep updates to your users table to a minimum.
But you also need to make sure you don’t constantly need to join these 2 tables after the partitioning or you might actually suffer performance decline.
17. Split the Big DELETE or INSERT Queries
If you need to perform a big DELETE or INSERT query on a live website, you need to be careful not to disturb the web traffic. When a big query like that is performed, it can lock your tables and bring your web application to a halt.Apache runs many parallel processes/threads. Therefore it works most efficiently when scripts finish executing as soon as possible, so the servers do not experience too many open connections and processes at once that consume resources, especially the memory.
If you end up locking your tables for any extended period of time (like 30 seconds or more), on a high traffic web site, you will cause a process and query pileup, which might take a long time to clear or even crash your web server.
If you have some kind of maintenance script that needs to delete large numbers of rows, just use the LIMIT clause to do it in smaller batches to avoid this congestion.
- while (1) {
- mysql_query("DELETE FROM logs WHERE log_date <= '2009-10-01' LIMIT 10000");
- if (mysql_affected_rows() == 0) {
- // done deleting
- break;
- }
- // you can even pause a bit
- usleep(50000);
- }
18. Smaller Columns Are Faster
With database engines, disk is perhaps the most significant bottleneck. Keeping things smaller and more compact is usually helpful in terms of performance, to reduce the amount of disk transfer.MySQL docs have a list of Storage Requirements for all data types.
If a table is expected to have very few rows, there is no reason to make the primary key an INT, instead of MEDIUMINT, SMALLINT or even in some cases TINYINT. If you do not need the time component, use DATE instead of DATETIME.
Just make sure you leave reasonable room to grow or you might end up like Slashdot.
19. Choose the Right Storage Engine
The two main storage engines in MySQL are MyISAM and InnoDB. Each have their own pros and cons.MyISAM is good for read-heavy applications, but it doesn't scale very well when there are a lot of writes. Even if you are updating one field of one row, the whole table gets locked, and no other process can even read from it until that query is finished. MyISAM is very fast at calculating SELECT COUNT(*) types of queries.
InnoDB tends to be a more complicated storage engine and can be slower than MyISAM for most small applications. But it supports row-based locking, which scales better. It also supports some more advanced features such as transactions.
20. Use an Object Relational Mapper
By using an ORM (Object Relational Mapper), you can gain certain performance benefits. Everything an ORM can do, can be coded manually too. But this can mean too much extra work and require a high level of expertise.ORM's are great for "Lazy Loading". It means that they can fetch values only as they are needed. But you need to be careful with them or you can end up creating to many mini-queries that can reduce performance.
ORM's can also batch your queries into transactions, which operate much faster than sending individual queries to the database.
Currently my favorite ORM for PHP is Doctrine. I wrote an article on how to install Doctrine with CodeIgniter.
21. Be Careful with Persistent Connections
Persistent Connections are meant to reduce the overhead of recreating connections to MySQL. When a persistent connection is created, it will stay open even after the script finishes running. Since Apache reuses it's child processes, next time the process runs for a new script, it will reuse the same MySQL connection.It sounds great in theory. But from my personal experience (and many others), this features turns out to be not worth the trouble. You can have serious problems with connection limits, memory issues and so on.
Apache runs extremely parallel, and creates many child processes. This is the main reason that persistent connections do not work very well in this environment. Before you consider using the mysql_pconnect() function, consult your system admin.
Note: This article was taken from http://net.tutsplus.com/tutorials/other/top-20-mysql-best-practices/comment-page-3/


Highlight Source Codes in Web Pages

Ubuntu users can download this using:
sudo apt-get install source-highlight
and the usage is like this:
source-highlight filename
If the filename is blah.extension, source-highlight creates blah.extension.html file in the same directory of filename.
The example C code below is about using sockets in POSIX type systems:
/* ** client.c -- a stream socket client demo */ #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <errno.h> #include <string.h> #include <netdb.h> #include <sys/types.h> #include <netinet/in.h> #include <sys/socket.h> #include <arpa/inet.h> #define PORT "3490" // the port client will be connecting to #define MAXDATASIZE 100 // max number of bytes we can get at once // get sockaddr, IPv4 or IPv6: void *get_in_addr(struct sockaddr *sa) { if (sa->sa_family == AF_INET) { return &(((struct sockaddr_in*)sa)->sin_addr); } return &(((struct sockaddr_in6*)sa)->sin6_addr); } int main(int argc, char *argv[]) { int sockfd, numbytes; char buf[MAXDATASIZE]; struct addrinfo hints, *servinfo, *p; int rv; char s[INET6_ADDRSTRLEN]; if (argc != 2) { fprintf(stderr,"usage: client hostname\n"); exit(1); } memset(&hints, 0, sizeof hints); hints.ai_family = AF_UNSPEC; hints.ai_socktype = SOCK_STREAM; if ((rv = getaddrinfo(argv[1], PORT, &hints, &servinfo)) != 0) { fprintf(stderr, "getaddrinfo: %s\n", gai_strerror(rv)); return 1; } // loop through all the results and connect to the first we can for(p = servinfo; p != NULL; p = p->ai_next) { if ((sockfd = socket(p->ai_family, p->ai_socktype, p->ai_protocol)) == -1) { perror("client: socket"); continue; } if (connect(sockfd, p->ai_addr, p->ai_addrlen) == -1) { close(sockfd); perror("client: connect"); continue; } break; } if (p == NULL) { fprintf(stderr, "client: failed to connect\n"); return 2; } inet_ntop(p->ai_family, get_in_addr((struct sockaddr *)p->ai_addr), s, sizeof s); printf("client: connecting to %s\n", s); freeaddrinfo(servinfo); // all done with this structure if ((numbytes = recv(sockfd, buf, MAXDATASIZE-1, 0)) == -1) { perror("recv"); exit(1); } buf[numbytes] = '\0'; printf("client: received '%s'\n",buf); close(sockfd); return 0; }
And this is a Java example about using Sockets in all platforms:
/** * SocketClient.java * Copyright (c) 2002 by Dr. Herong Yang */ import java.io.*; import java.net.*; public class SocketClient { public static void main(String[] args) { BufferedReader in = new BufferedReader(new InputStreamReader( System.in)); PrintStream out = System.out; try { Socket c = new Socket("localhost",8888); printSocketInfo(c); BufferedWriter w = new BufferedWriter(new OutputStreamWriter( c.getOutputStream())); BufferedReader r = new BufferedReader(new InputStreamReader( c.getInputStream())); String m = null; while ((m=r.readLine())!= null) { out.println(m); m = in.readLine(); w.write(m,0,m.length()); w.newLine(); w.flush(); } w.close(); r.close(); c.close(); } catch (IOException e) { System.err.println(e.toString()); } } private static void printSocketInfo(Socket s) { System.out.println("Remote address = " +s.getInetAddress().toString()); System.out.println("Remote port = " +s.getPort()); System.out.println("Local socket address = " +s.getLocalSocketAddress().toString()); System.out.println("Local address = " +s.getLocalAddress().toString()); System.out.println("Local port = " +s.getLocalPort()); } }
Monday, September 6, 2010
Linux, Windows and Mac

How OS users see their OS's and others?
Linux means black screen shit for windows users...
Also windows is full of white characters on a blue screen...
Thursday, August 5, 2010
examples on ifconfig, grep and awk

These examples are about "read ip address of linux interfaces" entry;
1) get interface list;
root@ismail-laptop:/usr/lib/cgi-bin# ifconfig | grep "Link encap"| awk -F ' ' '{print $1}'
eth0
eth2
lo
ppp0
root@ismail-laptop:/usr/lib/cgi-bin#
2) get mac address from each interfaces;
root@ismail-laptop:/usr/lib/cgi-bin# ifconfig | grep "HWaddr" | awk -F ' ' '{print $1 " - " $5}'
eth0 - 00:26:b9:9a:65:06
eth2 - c4:17:fe:1e:fe:6d
root@ismail-laptop:/usr/lib/cgi-bin#
3) get upload/download size for specific interface;
root@ismail-laptop:/usr/lib/cgi-bin# ifconfig ppp0 | grep "RX bytes" | awk -F ' ' '{print "download size: " $3 " " $4}'
download size: (5.8 MB)
root@ismail-laptop:/usr/lib/cgi-bin# ifconfig ppp0 | grep "RX bytes" | awk -F ' ' '{print "download size: " $7 " " $8}'
download size: (2.3 MB)
root@ismail-laptop:/usr/lib/cgi-bin#
Using Beanshell Scripts in cgi-bin Directory
In this tutorial, we demonstrate to use Bean Shell Java interpreter as a cgi language. Beanshell is a Java interpreter that can be called dynamically in Java applications or linux console. You can download and install Beanshell in Ubuntu using
# sudo apt-get install bsh
After installing you can test it by typing bsh in linux shell:
root@stdio:/# bsh
BeanShell 2.0b4 - by Pat Niemeyer (pat@pat.net)
bsh % System.out.println("Hello world!");
Hello world!
bsh % double[] d=new double[]{1,2,3.14159};
bsh % for (int i=0;i
System.out.println("d["+i+"] is "+d[i]);
}
d[0] is 1.0
d[1] is 2.0
d[2] is 3.14159
You have to create a file called .jline-bsh.Interpreter.history in directory /var/www and this file has to be writable rights. You can create and give writable rights like this:
# touch /var/www/.jline-bsh.Interpreter.history
# chmod a+w /var/www/.jline-bsh.Interpreter.history
Now we can create our Beanshell cgi script using a text editor like vim.
# cd /usr/lib/cgi-bin/
stdio:/usr/lib/cgi-bin# vim 1.bsh
A sample 1.bsh file includes these lines of codes:
#!/usr/bin/bsh
System.out.println("Content-type: text/html\n\n");
System.out.println("Hello from java cgi");
System.out.println(System.getenv("QUERY_STRING"));
In first line of this script, we say this script will be handled using /usr/bin/bsh.
Secondly, content type of this file is text/html so browser will display the output as html.
In third line, we send a hello world string to client and finally we write variables which are defined in URL.
In order to run this code, we have to give executable rights to file using
# chmod a+x 1.bsh
Now, we are ready to run this code using our browser. Be sure that your apache server is running using
# sudo /etc/init.d/apache2 status
and it is not running use
# sudo /etc/init.d/apache2 start
to start it. After that, open a browser and type,

# sudo apt-get install bsh
After installing you can test it by typing bsh in linux shell:
root@stdio:/# bsh
BeanShell 2.0b4 - by Pat Niemeyer (pat@pat.net)
bsh % System.out.println("Hello world!");
Hello world!
bsh % double[] d=new double[]{1,2,3.14159};
bsh % for (int i=0;i
System.out.println("d["+i+"] is "+d[i]);
}
d[0] is 1.0
d[1] is 2.0
d[2] is 3.14159
# touch /var/www/.jline-bsh.Interpreter.history
# chmod a+w /var/www/.jline-bsh.Interpreter.history
Now we can create our Beanshell cgi script using a text editor like vim.
# cd /usr/lib/cgi-bin/
stdio:/usr/lib/cgi-bin# vim 1.bsh
A sample 1.bsh file includes these lines of codes:
#!/usr/bin/bsh
System.out.println("Content-type: text/html\n\n");
System.out.println("Hello from java cgi");
System.out.println(System.getenv("QUERY_STRING"));
In first line of this script, we say this script will be handled using /usr/bin/bsh.
Secondly, content type of this file is text/html so browser will display the output as html.
In third line, we send a hello world string to client and finally we write variables which are defined in URL.
In order to run this code, we have to give executable rights to file using
# chmod a+x 1.bsh
Now, we are ready to run this code using our browser. Be sure that your apache server is running using
# sudo /etc/init.d/apache2 status
and it is not running use
# sudo /etc/init.d/apache2 start
to start it. After that, open a browser and type,
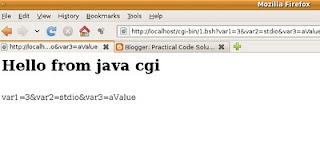
http://localhost/cgi-bin/1.bsh
If everything is ok, we can see something like that:

We can pass some variables like this
http://localhost/cgi-bin/1.bsh?var1=3&var2=stdio&var3=aValue

read ip address of linux interfaces
you can read ip configuration with "ifconfig" command. but this command returns lots of information. if you need just some specific interface address, you have to use longer commands ;)
for example;
my notebook's current ifconfig command output is;
ismail@ismail-laptop:~$ ifconfig
eth0 Link encap:Ethernet HWaddr 00:26:b9:9a:65:06
UP BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
Memory:f6ae0000-f6b00000
eth2 Link encap:Ethernet HWaddr c4:17:fe:1e:fe:6d
inet6 addr: fe80::c617:feff:fe1e:fe6d/64 Scope:Link
UP BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:35
TX packets:0 errors:12 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
Interrupt:17 Base address:0xc000
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:3582 errors:0 dropped:0 overruns:0 frame:0
TX packets:3582 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:456842 (456.8 KB) TX bytes:456842 (456.8 KB)
ppp0 Link encap:Point-to-Point Protocol
inet addr:178.244.166.249 P-t-P:10.64.64.64 Mask:255.255.255.255
UP POINTOPOINT RUNNING NOARP MULTICAST MTU:1500 Metric:1
RX packets:5463 errors:0 dropped:0 overruns:0 frame:0
TX packets:5612 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:3
RX bytes:5031133 (5.0 MB) TX bytes:1609578 (1.6 MB)
i'm using mobile modem now. so i am using ppp0 interface to connect to internet.
for example a)
i want to read only my ppp0 interface's ip address.
ismail@ismail-laptop:~$ ifconfig ppp0 | grep "inet addr" | awk -F ' ' '{ print $2}'| awk -F ':' '{print $2}'
178.244.166.249
lets explain step by step this command;
ifconfig ppp0 command output is;
ismail@ismail-laptop:~$ ifconfig ppp0
ppp0 Link encap:Point-to-Point Protocol
inet addr:178.244.166.249 P-t-P:10.64.64.64 Mask:255.255.255.255
UP POINTOPOINT RUNNING NOARP MULTICAST MTU:1500 Metric:1
RX packets:5717 errors:0 dropped:0 overruns:0 frame:0
TX packets:5871 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:3
RX bytes:5204480 (5.2 MB) TX bytes:1678921 (1.6 MB)
i can eliminate other interfaces with ifconfig ppp0 command. if this output is sent to grep command with "|" argument, i can select only the line which has ip address included in. like this;
ismail@ismail-laptop:~$ ifconfig ppp0 | grep "inet addr"
inet addr:178.244.166.249 P-t-P:10.64.64.64 Mask:255.255.255.255
i use "inet addr" keyword because, i think this keyword is unique for ifconfig command output. and now i need to start doing some string manipulation. for example we can seperate this line by blanks. awk command is able to do this features as following;
ismail@ismail-laptop:~$ ifconfig ppp0 | grep "inet addr" | awk -F ' ' '{print $2}'
addr:178.244.166.249
-F means "find".
after than ' ' means: seperate by the blanks
and after than '{ print $2 }', prints the second seperated element. if we use $1, we can see "inet" output.
and last step. we have to use awk again for seperating by ":" keyword for read only ip address part.
ismail@ismail-laptop:~$ ifconfig ppp0 | grep "inet addr" | awk -F ' ' '{print $2}' | awk -F ':' '{ print $2 }'
178.244.166.249
using like things on last command and finally we can read only ip address.
and last trick. if you will use these commands on shell script and define crontab schedule you have to use fullpath for all commands. so, we have to find fullpath informations about using commands. we can use whereis command to find fullpath info.
ismail@ismail-laptop:~$ whereis ifconfig
ifconfig: /sbin/ifconfig /usr/share/man/man8/ifconfig.8.gz
ismail@ismail-laptop:~$ whereis grep
grep: /bin/grep /usr/share/man/man1/grep.1.gz
ismail@ismail-laptop:~$ whereis awk
awk: /usr/bin/awk /usr/lib/awk /usr/share/awk /usr/share/man/man1/awk.1.gz
ismail@ismail-laptop:~$
and final command;
ismail@ismail-laptop:~$ /sbin/ifconfig ppp0 | /bin/grep "inet addr" | /usr/bin/awk -F ' ' '{ print $2}' | /usr/bin/awk -F ':' '{ print $2 }'
178.244.166.249
In these examples, you have to know interface name to extract ip address informations. for example we knew ppp0 interface name. if you don't know interface name, you can read next entry :)
for example;
my notebook's current ifconfig command output is;
ismail@ismail-laptop:~$ ifconfig
eth0 Link encap:Ethernet HWaddr 00:26:b9:9a:65:06
UP BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
Memory:f6ae0000-f6b00000
eth2 Link encap:Ethernet HWaddr c4:17:fe:1e:fe:6d
inet6 addr: fe80::c617:feff:fe1e:fe6d/64 Scope:Link
UP BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:35
TX packets:0 errors:12 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
Interrupt:17 Base address:0xc000
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:3582 errors:0 dropped:0 overruns:0 frame:0
TX packets:3582 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:456842 (456.8 KB) TX bytes:456842 (456.8 KB)
ppp0 Link encap:Point-to-Point Protocol
inet addr:178.244.166.249 P-t-P:10.64.64.64 Mask:255.255.255.255
UP POINTOPOINT RUNNING NOARP MULTICAST MTU:1500 Metric:1
RX packets:5463 errors:0 dropped:0 overruns:0 frame:0
TX packets:5612 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:3
RX bytes:5031133 (5.0 MB) TX bytes:1609578 (1.6 MB)
i'm using mobile modem now. so i am using ppp0 interface to connect to internet.
for example a)
i want to read only my ppp0 interface's ip address.
ismail@ismail-laptop:~$ ifconfig ppp0 | grep "inet addr" | awk -F ' ' '{ print $2}'| awk -F ':' '{print $2}'
178.244.166.249
lets explain step by step this command;
ifconfig ppp0 command output is;
ismail@ismail-laptop:~$ ifconfig ppp0
ppp0 Link encap:Point-to-Point Protocol
inet addr:178.244.166.249 P-t-P:10.64.64.64 Mask:255.255.255.255
UP POINTOPOINT RUNNING NOARP MULTICAST MTU:1500 Metric:1
RX packets:5717 errors:0 dropped:0 overruns:0 frame:0
TX packets:5871 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:3
RX bytes:5204480 (5.2 MB) TX bytes:1678921 (1.6 MB)
i can eliminate other interfaces with ifconfig ppp0 command. if this output is sent to grep command with "|" argument, i can select only the line which has ip address included in. like this;
ismail@ismail-laptop:~$ ifconfig ppp0 | grep "inet addr"
inet addr:178.244.166.249 P-t-P:10.64.64.64 Mask:255.255.255.255
i use "inet addr" keyword because, i think this keyword is unique for ifconfig command output. and now i need to start doing some string manipulation. for example we can seperate this line by blanks. awk command is able to do this features as following;
ismail@ismail-laptop:~$ ifconfig ppp0 | grep "inet addr" | awk -F ' ' '{print $2}'
addr:178.244.166.249
-F means "find".
after than ' ' means: seperate by the blanks
and after than '{ print $2 }', prints the second seperated element. if we use $1, we can see "inet" output.
and last step. we have to use awk again for seperating by ":" keyword for read only ip address part.
ismail@ismail-laptop:~$ ifconfig ppp0 | grep "inet addr" | awk -F ' ' '{print $2}' | awk -F ':' '{ print $2 }'
178.244.166.249
using like things on last command and finally we can read only ip address.
and last trick. if you will use these commands on shell script and define crontab schedule you have to use fullpath for all commands. so, we have to find fullpath informations about using commands. we can use whereis command to find fullpath info.
ismail@ismail-laptop:~$ whereis ifconfig
ifconfig: /sbin/ifconfig /usr/share/man/man8/ifconfig.8.gz
ismail@ismail-laptop:~$ whereis grep
grep: /bin/grep /usr/share/man/man1/grep.1.gz
ismail@ismail-laptop:~$ whereis awk
awk: /usr/bin/awk /usr/lib/awk /usr/share/awk /usr/share/man/man1/awk.1.gz
ismail@ismail-laptop:~$
and final command;
ismail@ismail-laptop:~$ /sbin/ifconfig ppp0 | /bin/grep "inet addr" | /usr/bin/awk -F ' ' '{ print $2}' | /usr/bin/awk -F ':' '{ print $2 }'
178.244.166.249
In these examples, you have to know interface name to extract ip address informations. for example we knew ppp0 interface name. if you don't know interface name, you can read next entry :)
Subscribe to:
Posts (Atom)